
DATA Analytics Pipelines :
Préparation / Analyse / Déploiement
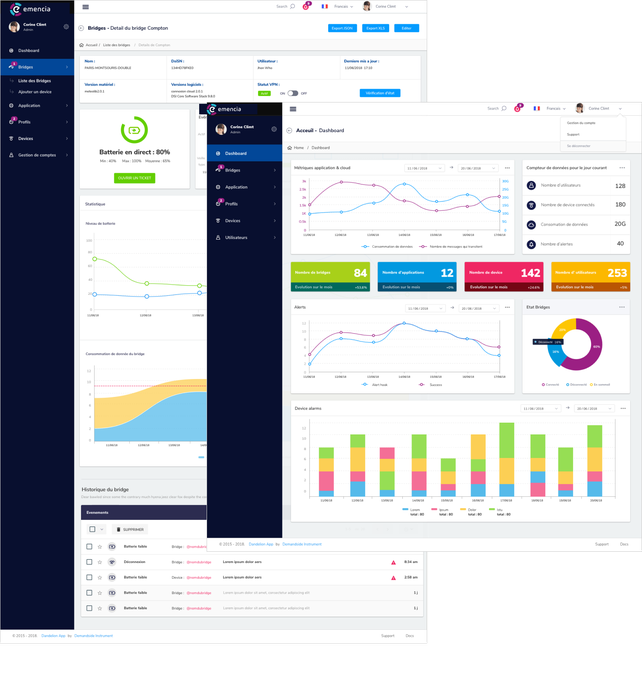
Création d'un data pipeline
DATA Analytics Pipelines
Nos Data Architects vous accompagnent sur votre infrastructure et la mise en place de pipelines de CI/CD sécurisés et robustes afin de gagner du temps lors de vos déploiements de code
Nos Data Engineers experts vous accompagneront dans la construction de pipelines optimisés pour alimenter vos modèles en data (streaming ou batch) tout en veillant au maintien de la qualité dans le temps.
1. Préparation
Intégration des données
Rassembler les données à partir de sources variées, telles que des bases de données, des fichiers, des APIs, ou des données provenant de capteurs par exemple
Exploration des données
Analyse des structures, formats, et caractéristiques ainsi que et leurs problèmes éventuels. Cela aide à identifier les valeurs manquantes, les duplications ou les incohérences et à préparer la phase de nettoyage. Une fois cette première évaluation effectuée, nous pouvons procéder au nettoyage des données
Nettoyage des données
Cette phase consiste en la correction des erreurs ou des incohérences trouvées lors de l'exploration des données. Par exemple traitement des valeurs nulles, conversion de formats de données, interpolation ou remplacement des données manquantes. A l'issue de cette phase le dataset sera exploitable, nous procédons alors à d'éventuelles transformations en vue de l'analyse définitive
Transformation des données
Phase où les données sont modifiées pour les adapter aux besoins spécifiques de l'analyse. Cela peut inclure la normalisation des données pour les mettre à l'échelle, la conversion de formats de données, l'agrégation, la discrétisation. Exemple d'aggrégation: grouper des points de données par période de temps pour réduire le volume de données si le besoin existe (par exemple un capteur délivre des points de données toutes les secondes et nous n'avons besoin que d'une échelle de la minute pour l'analyse)
2. Analyse
Analyse des KPI
Identification des structures de données et opérations pertinentes à effectuer pour chaque key performance indicator. Extraction et processing des données pertinentes par KPI
Prototypage des visualisations
Séléction des modèles de charts les mieux adaptés à chaque KPI et affinage en fonction les types de données disponibles et du résultat attendu (séries temporelles, catégorielles, numériques, etc)
3. Déploiement
Création d'un data pipeline
Les opérations ci-dessus sont automatisées dans un process. En entrée la data brute passera par différentes étapes de traitement pour en sortie créer les charts et éléments prévus. En cas de nouvelles données ce process peut être lancé pour updater les visualisations
Assemblage du dashboard
Travail de frontend pour présenter les différentes parties du dashboard: charts, navigation, pages ou structure de l'application. Intégration des contraintes de sécurité (login, api keys ou autre selon projet)
Intégration du dashboard
Dans un site existant ou sous forme de service indépendant sécurisé avec utilisateurs enregistrés et autorisations
Déploiement du service en production
Déploiement du service en production : Cloud, Docker, Kubernetes, Ansible. Mise à disposition de la donnée via une API, intégration à un site Internet existant ou une application métier. Génération et distribution des extracts de rapports automatisés (par email, format PDF, CSV, XLS....)
















Publications


MLOps - quand le DevOps rencontre le machine Learning
Le MLOps, également connu sous le nom de DevOps appliqué au Machine Learning, est une approche pluridisciplinaire conçue pour intégrer le développement de modèles de machine learning (ML) et leur mise en œuvre pratique.
Cette pratique s'inspire des principes du DevOps, comme l'intégration et la livraison continue, ainsi que l'automatisation des processus informatiques, et les adapte spécifiquement au domaine du machine learning.
Utiliser une IA locale pour documenter du code
La puissance des modèles de language open source augmente, ouvrant des possibilités nouvelles. Dans cet exemple nous allons utiliser Mistral 7B instruct, un des meilleurs modèle de taille modeste à ce jour, pour générer des docstrings pour du code Python. Un avantage essentiel de cette technique est qu'elle permet de garder le code privé, rien n'est envoyé sur des plateformes externes, assurant une confidentialité compatible avec une utilisation en entreprise.

LocalLm : une IA locale en Python
Face à ChatGPT et autres large language models (LLM) fermés, des alternatives open source se développent. De plus en plus de models open source font leur apparition : les Llama, Mistral et autres Falcon et consorts. Cet écosystème émergent permet d'envisager une utilisation interne en entreprise, hors plateformes géantes. Même si les coûts et la technologie restent incertains et en constante évolution, une telle approche permet de préserver la confidentialité des données, en ne les envoyant pas sur des plateformes externes.

C-TEC Constellium Technology Center - Développement d'une plateforme web de calculs scientifiques et d'applications métiers
Constellium est un leader mondial dans le développement, la fabrication et le recyclage de produits et solutions en aluminium avec près de 12 500 employés et 25 sites de production dans le monde.

Utiliser une IA locale dans Django
Ceci est une introduction l'IA prend de plus en plus de place, de plus en plus vite. Depuis quelques temps a émergé un mouvement open source autour notamment de Llama.cpp.

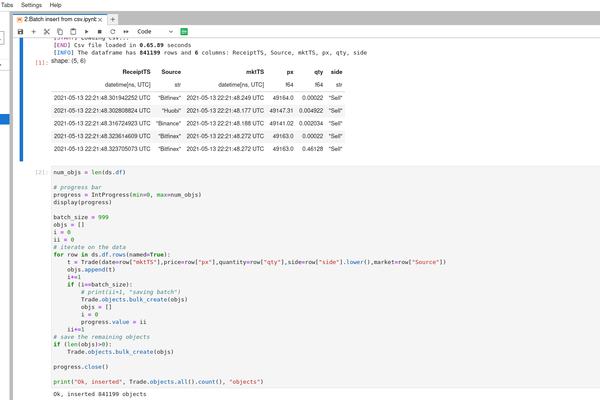
Utiliser des notebooks Jupyter Lab en contexte Django
Python dispose des meilleurs outils de data science. Nous allons utiliser ces outils dans le contexte d'un projet Django pour manipuler et analyser des données. Installation du stack Détail des librairies utilisées: Jupyter lab pour les notebooks Django extensions pour faciliter le lancement des notebooks Polars pour les dataframes et…
Nous contacter
- contact@emencia.com
- +33 1 47 20 23 01
- 117 rue de Charenton, 75012 Paris France