
Python dispose des meilleurs outils de data science. Nous allons utiliser ces outils dans le contexte d'un projet Django pour manipuler et analyser des données.
Installation du stack
Détail des librairies utilisées:
- Jupyter lab pour les notebooks
- Django extensions pour faciliter le lancement des notebooks
- Polars pour les dataframes et Dataspace pour faciliter l'analyse de données
Le code des exemples mentionnés dans cet article est disponible sur le repository django-datastack
Installons les dépendances nécessaires:
pip install django-extensions jupyterlab dataspace
Ajouter "django_extensions" dans le setting INSTALLED_APPS
Configuration des notebooks
Créons un dossier notebooks dans un projet Django et ajoutons y un fichier d'initialisation:
mkdir notebooks
cd notebooks
touch __init__.py
Le nouveau fichier __init__.py contient des éléments de configuration pour lancer le notebook en contexte Django:
import sys
from pathlib import Path
import os
os.environ["DJANGO_ALLOW_ASYNC_UNSAFE"] = "true"
file = Path(__file__).resolve()
parent, root = file.parent, file.parents[1]
sys.path.append(str(root))
Lancement
Lançons les notebooks:
python manage.py shell_plus --lab
Une fenêtre va s'ouvrir automatiquement dans le navigateur. Créons un premier notebook en séléctionnant "Notebooks / Django Shell Plus" et vérifions que nous pouvons effectuer des queries orm:
%run __init__
from django.contrib.auth.models import User
User.objects.all()
La première ligne est requise pour initialiser l'environnement à partir du script que nous avons mis en place précédemment.
Insérer des données depuis des fichiers csv
Maintenant que notre environnement notebook est correctement configuré nous allons en tirer profit pour injecter des données dans la base Django à partir de fichiers csv
Charger des données
Nous utiliserons un dataset de market data historique détaillant les échanges Bitcoin/USDT sur différents exchanges. Créons une app Trades contenant un modèle Trade simple:
from django.db import models
SIDE = [("buy", "buy"), ("sell", "sell")]
class Trade(models.Model):
date = models.DateTimeField()
price = models.FloatField()
quantity = models.FloatField()
market = models.CharField(max_length=255)
side = models.CharField(max_length=4, choices=SIDE)
def __str__(self) -> str:
return f"${self.market} ${self.date}"
Créons un notebook et chargeons un fichier csv:
%run __init__
import dataspace
from trades.models import Trade
ds = dataspace.from_csv("data/BTC-USDT-1min.csv")
ds.show()

Note: nous utilisons ici une fonction de la librairie Dataspace. Il est également possible d'utiliser d'autres librairies plus classiques pour charger le csv : Pandas ou Polars notamment.
Insertion simple
Les données étant peu volumineuses (5400 datapoints environ) nous allons les injecter en db avec des queries insert simples en itérant sur la dataframe:
for row in ds.df.rows(named=True):
Trade.objects.create(
date=row["mktTS"],
price=row["px"],
quantity=row["qty"],
side=row["side"].lower(),
market=row["Source"]
)
print("ok")
Vérifions maintenant que les données ont bien été insérées avec un query select:
qs = Trade.objects.all()
ds = dataspace.from_django(qs)
ds.show()

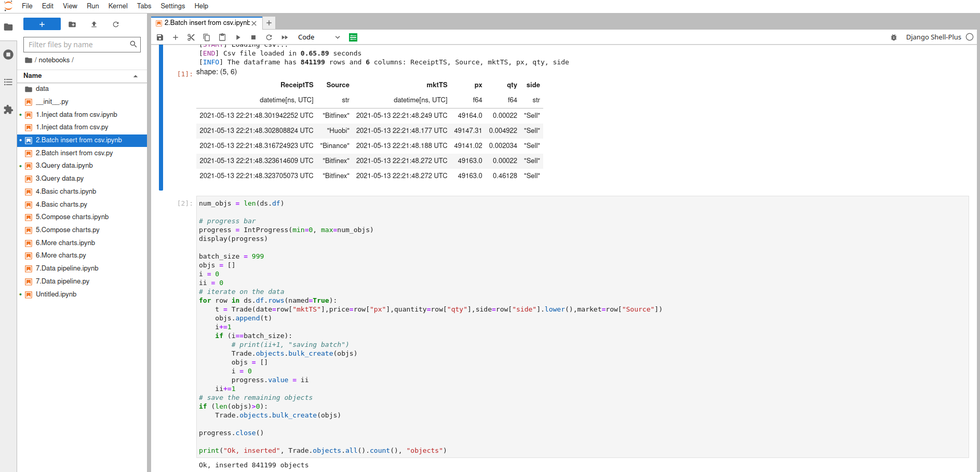
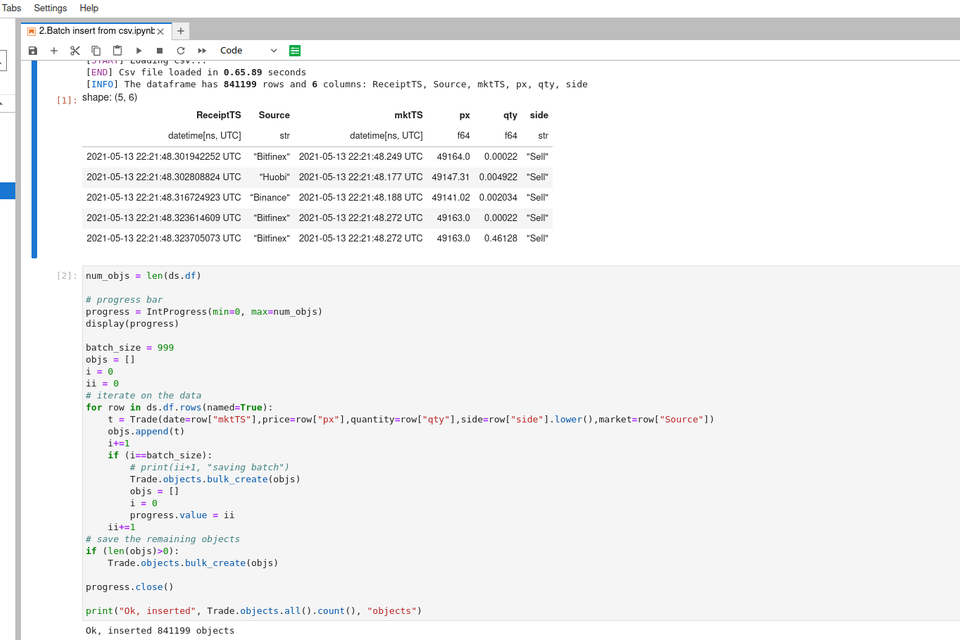
Batch insert
Injectons maintenant une quantité de données plus importante et voyons comment utiliser le batch insert. Nous allons charger deux fichiers csv et les fusionner dans une dataframe avant de lancer les queries d'insertion:
%run __init__
import polars as pl
import dataspace
from trades.models import Trade
ds = dataspace.from_csv("data/bitcoin1.csv")
ds2 = dataspace.from_csv("data/bitcoin2.csv")
ds.df = pl.concat([ds.df, ds2.df], rechunk=True)
ds.show()

Nous allons injecter les données en base par tranche en utilisant bulk_create:
batch_size = 999
objs = []
i = 0
# iterate on the data
for row in ds.df.rows(named=True):
t = Trade(date=row["mktTS"],price=row["px"],quantity=row["qty"],side=row["side"].lower(),market=row["Source"])
objs.append(t)
i+=1
if (i==batch_size):
# print("saving batch")
Trade.objects.bulk_create(objs)
objs = []
i = 0
# save the remaining objects
if (len(objs)>0):
Trade.objects.bulk_create(objs)
print("Ok, got", Trade.objects.all().count(), "Trade objects in database")
Pour plus d'efficacité et de confort il est possible d'ajouter une progress bar: voir le notebook exemple.
Workflow git
Pour une organisation optimale il est conseillé de ne pas partager les fichiers notebooks .ipynb dans un repository: ils sont trop volumineux. La solution consiste à utiliser Jupytext pour créer des fichiers .py mirroir et les partager.
pip install jupytext
Pour pairer un notebook: dans le menu "View" séléctionner "Activate Command Palette", et séléctionner "Pair Notebook with percent Script":

Ceci va créer un fichier .py du même nom que le notebook en mirroir. Ajouter *.ipynb dans le .gitignore et committer uniquement les fichiers python.
Pour ouvrir un fichier python en temps que notebook faire un clic droit dessus et sélectionner "Open with" > "Notebook".
Et ensuite ?
Maintenant la donnée en base il est facile de lancer des queries Django classiques et charger des dataframes. Nous verrons dans un prochain article comment utiliser un stack de data analytics pour prototyper un dashboard avec des charts.
Exemples et notebooks:
Repository: django-datastack
Notebooks exemple: